特征平台(二)
整体架构
在上篇文章中主要是叙述了特征管理系统的顶层设计,从业务的角度对其进行了产品定位,根据它的定位将其划分为元数据管理、特征加工、特征服务三个功能模块,并简要的描述了实时特征计算的大致实现流程。本文再细化特征管理系统的实现。
用例
在做详细设计前,首先需要清楚用户如何与本系统进行交互,根据两者之间的交互动作来分解系统功能和做技术选型。
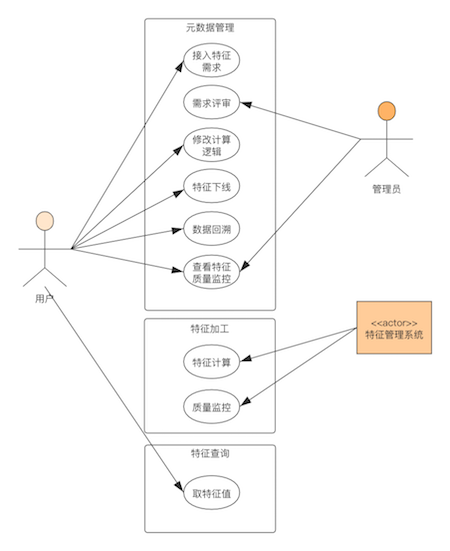
从用例图中,可以看出每个子模块需要提供的必要功能。在知道了模块的基本功能之后,再根据一个实际的案例将各个功能模块串联起来。
- 用户提了一个接入实时特征的需求,经过需求评审,可以接入特征管理系统;
- 然后触发特征上线动作,特征加工模块监测有新任务来了之后创建实时特征任务;
- 采集实时特征任务在执行过程中的监控指标,将监控数据发送到Druid中;
- 元数据管理模块中的监控子模块会将监控指标可视化的展示出来,并且根据规则来判断是否要触发任务异常报警;
- 模型服务通过特征的元数据找到其对应的集群地址来获取特征值。
架构图
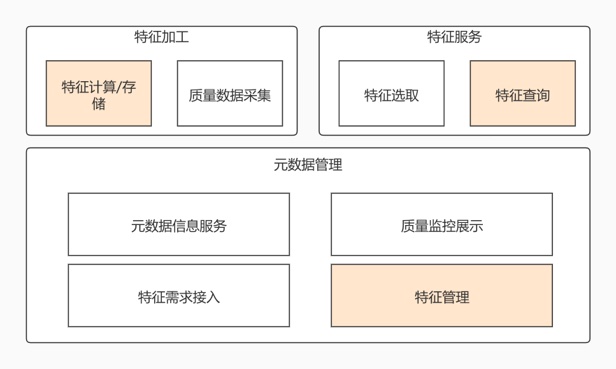
功能架构图
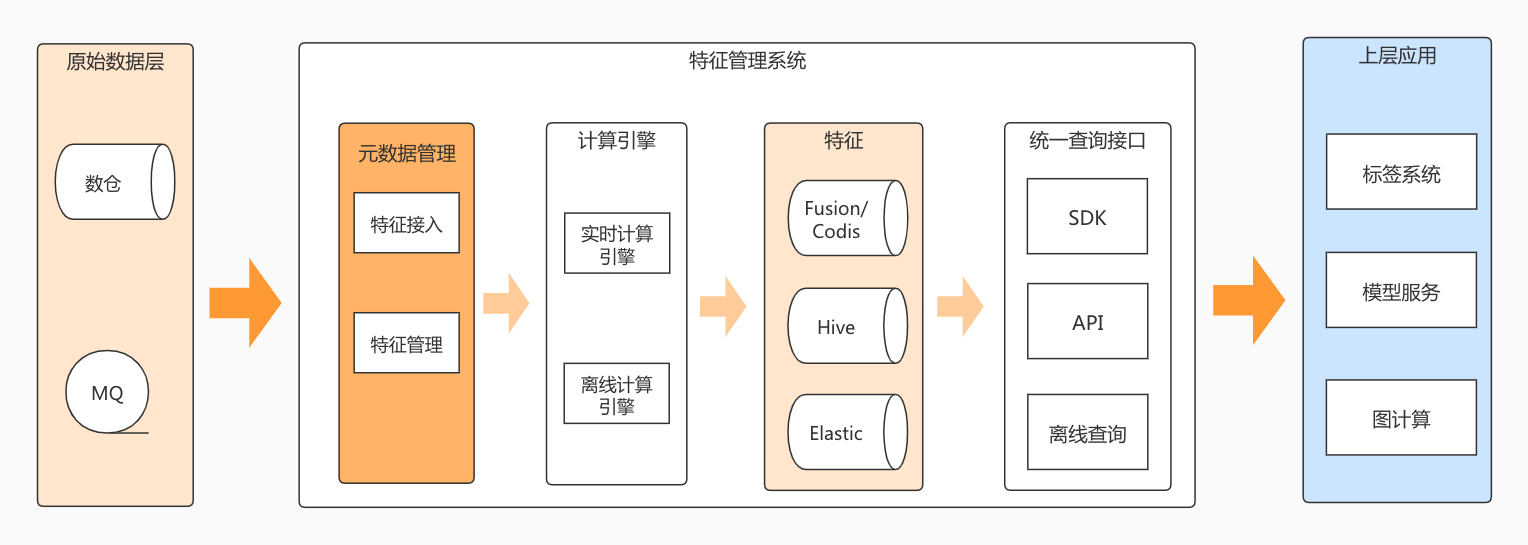
数据处理架构图
实体设计
核心流程上的实体
对应的ER图如下:
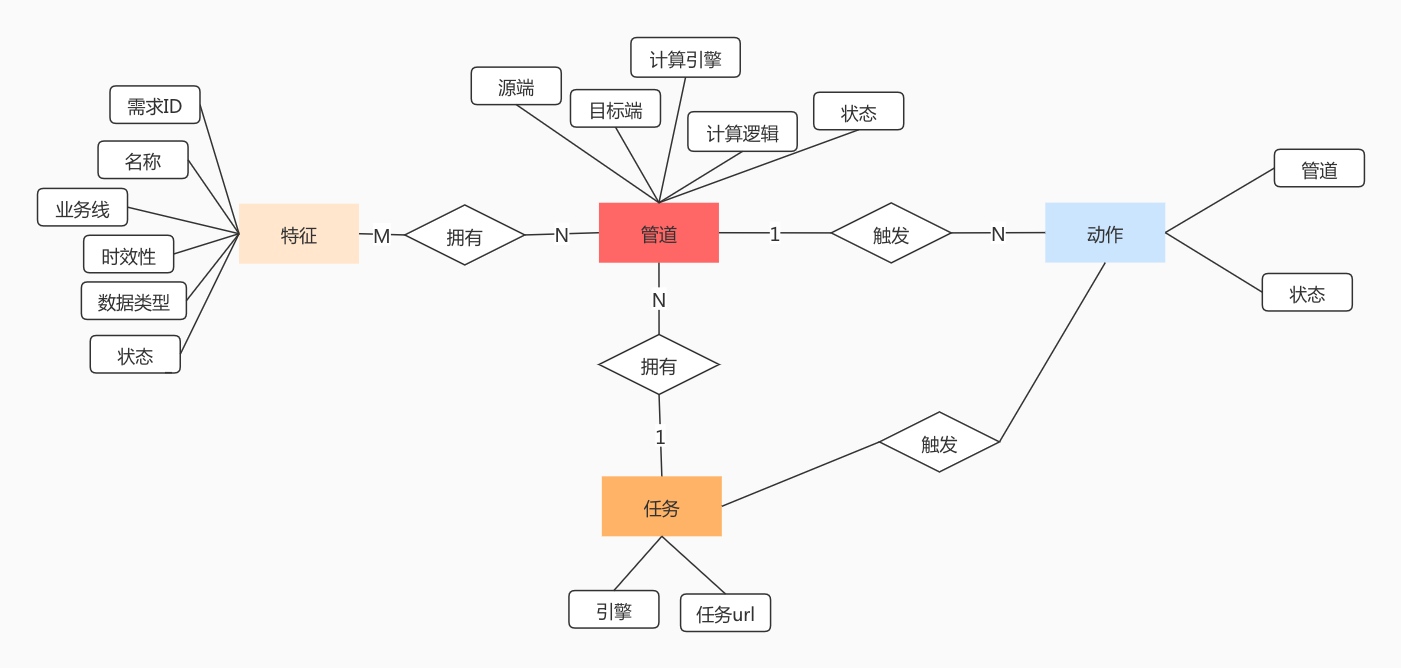
根据用例,可以得出以下必要的实体:
- 需求 记录用户提交的需求的详细信息
- 特征 这是系统中的核心,整个系统都是围绕着特征提供服务的
- 动作 操作特征出发的动作,特征加工模块会监控这个动作来提供相关的信息
- 任务 记录建立的计算引擎任务
特征计算过程可以看成是一个管道,原始数据经过经过一个管道之后变成另外一种数据,因此系统要再抽象出一个必要的实体:
- 管道 包含有源端、目标端、计算逻辑。由于同一个特征可能存储在不同的介质中,因此它可能会存在多个管道。管道也是本系统最核心的概念。一切操作都是基于管道的。
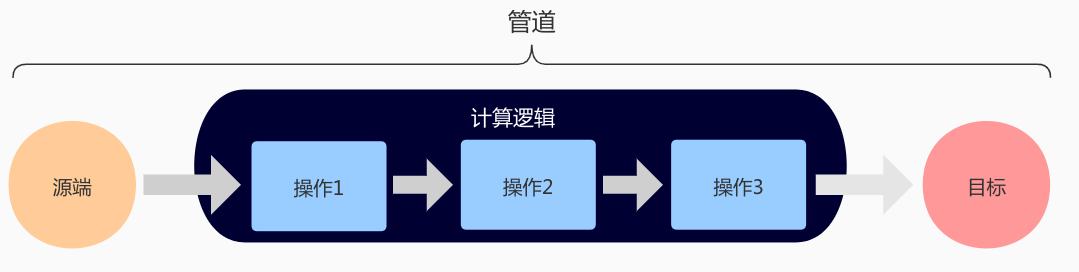
同一个特征可能存储在不同的DB中,例如:乘客大宽表,乘客特征的存储介质有hive、es、fusion,在这种情况下就需要建立多个管道来执行计算任务。一个计算逻辑也有可能会产出多个特征,例如:一个topic会产出发单数、完单数标签,因此管道也可以同时对应多个特征。
当特征上下线时,实质就是触发其对应的管道产生一个动作,然后根据这个动作再生成一个对应的计算任务。由于可能会将不同的管道计算逻辑放置到一个计算逻辑去执行,因此一个任务对应了多个管道。
ER图中只包含了执行一个特征计算任务所需要的所有信息,在实际的系统中,还会有额外的信息,例如:添加/更新时间,创建人等等。根据这个ER图就可以开发出系统的核心功能了,其它的辅助功能或者辅助信息可在实际开发时根据需要添加。
其它实体
- 数据源 记录数据源的详细信息
- 关系表 记录实体之间的关联关系
- 任务历史 记录任务的执行历史
- 特征变更表 记录特征的变更历史
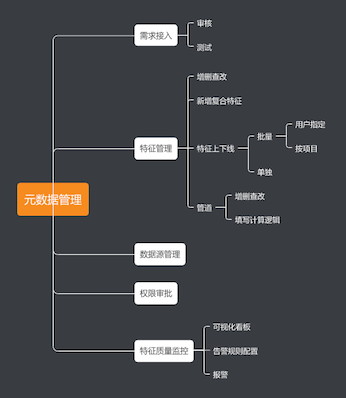
元数据管理
元数据管理的主体功能是特征上线、特征质量监控,其它的模块都是对主体流程的辅助。每个模块的功能边界可以参考文章(1)。
其大体功能如下:
特征上下线
由于特征的计算被抽象成管道,因此特征的上下线本质上就是对管道的上下线,对特征的所有动作都会反应到管道上。特征上线就是将管道合并到正在执行中的任务或者创建一个新的任务,特征下线就是从正在执行中的任务中抽离出对应的管道。
因此特征上线概念更严格一点就是(特征,管道)二元组的上线,将特征对应的管道部署到线上。例如 (用户完单数,hive-fusion)的上线,不会触发(用户完单数,hive-es)的上线。特征下线同理。
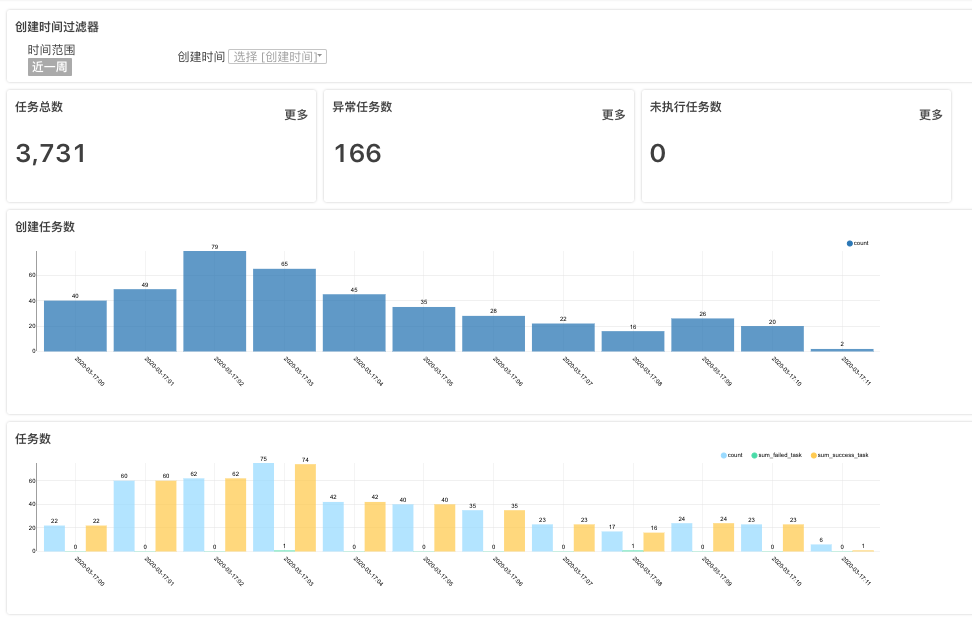
特征质量监控
这个模块是用于保障特征质量稳定性的,良好的特征质量才能向外保证特征是可靠的,才能将特征和平台推广出去。
以可视化的看板形式展示与此特征相关的质量数据
特征任务
特征加工任务本质上就是将一个或多个相应的管道合并成一个计算任务。
特征动作解析
整体流程如下:
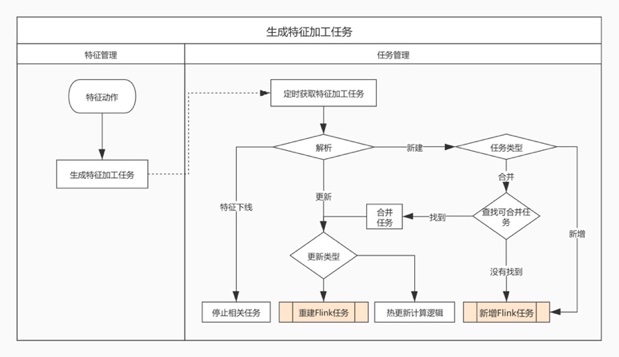
这个流程的重点是查找可以合并任务,前提是理解任务与管道之间关系。他们之间的关系用以下过程表达
1 |
|
判断管道是否能进行合并:
- 管道如果设置为独立任务,则不会执行合并
- 同一个组下的管道会进行合并
- 根据源端、目标端、计算逻辑判断是否能进行合并,例如:(hive db.table1, hive db.table2, select {tag} from table) ,这种情况下就是可以合并的。如果源端类型为消息队列的话,一般都是可以执行合并的。
- 如果源端类型为消息队列的话且qps较低,一般都是可以执行合并的。
执行引擎的选择
可选的执行引擎:
- flink 主要是用来处理实时数据,即管道的源端为mq
- spark 用来处理离线数据
- jvm进程 主要执行一些测试,例如在计算任务正式上线前,可通过jvm进程的方式来验证计算逻辑是否正确
flink引擎
大致流程如下:
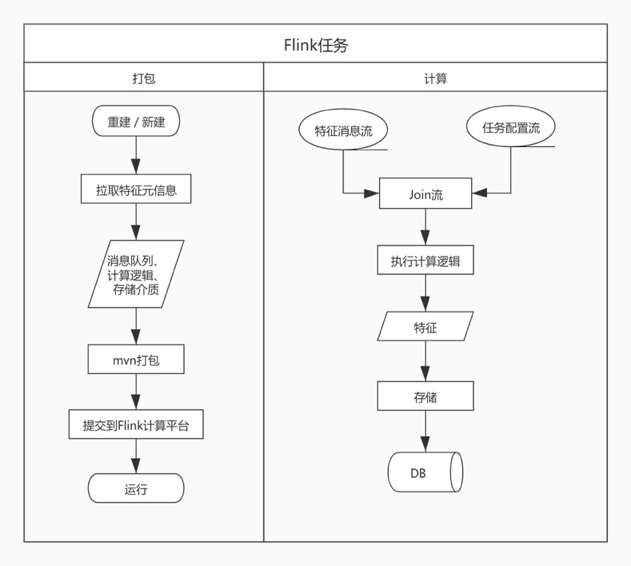
主要是分成两块,任务打包,计算逻辑的封装
由于计算任务的多变性,这里会提供一个基本的生产样例,主要是用来迁移torrent的。
后面会根据需求来提供更加丰富的样例。