特征平台(一)
背景
实时特征对运营活动是必不可少的,特征的质量也会对业务产生直接的影响。但是由于当前没有一个统一的实时特征接入和生产平台,导致特征的产出过程过于混乱,实时特征的质量也是不可控的。当前现象及主要问题有:
- 存在很多不同人开发的生产实时特征的工程,而且未来还会有更多。沟通、开发成本高;
- 很多特征的信息只存在于相应的工程代码中。没有被管理起来,信息缺失,难以追查特征逻辑并且其它项目很难复用;
- 没有质量监控。不能及时发现异常;计算逻辑问题难以排查。
这些问题已经对业务的扩展造成阻碍,因此需要对系统进行一次重构来解决这些问题。
注意:理解端到端对理解整个系统的设计非常重要,特征计算其实就是端到端的过程,将hive中的数据转存到fusion,mq中的数据转存到fusion、hive中,计算过程只是在时效上有区别,因此在设计整个系统流程的时候,不会着重区分实时计算和离线计算。
产品定位分析
产品架构
当前的产品架构为:
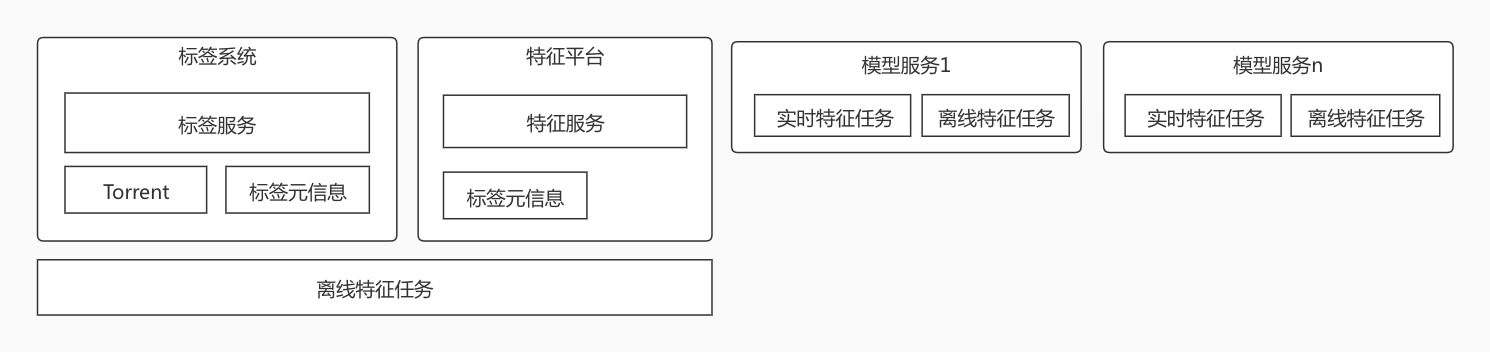
当前的系统虽然可以满足功能需求,但是在架构上没统一组织起来。模块间的耦合性太强,且特征的元数据都没有被统一管理起来。这些问题会使上线周期长、排查异常问题艰难,产品的扩展性也不是很好。
根据产品的特性进行模块划分和分层,将具有相同特性的项目划分成一个大的产品,再根据每个产品的功能进行分层。在划分后,每个产品都有了明确的定位,只需要专注于自己的逻辑。重构后的产品架构为:
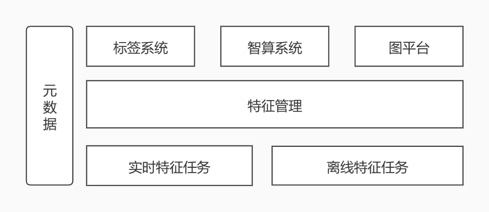
特征是整个系统的核心数据,所有上层应用都要依赖特征来提供相应的服务,因此将所有与特征相关的功能聚合到一起成为一个系统,特征处理相关的功能尽量与其它系统在功能上解耦。
特征管理系统
因此有一个完善的特征管理系统非常重要,在开发之前,先根据特征的生命周期来分析特征管理系统应该具有的功能。
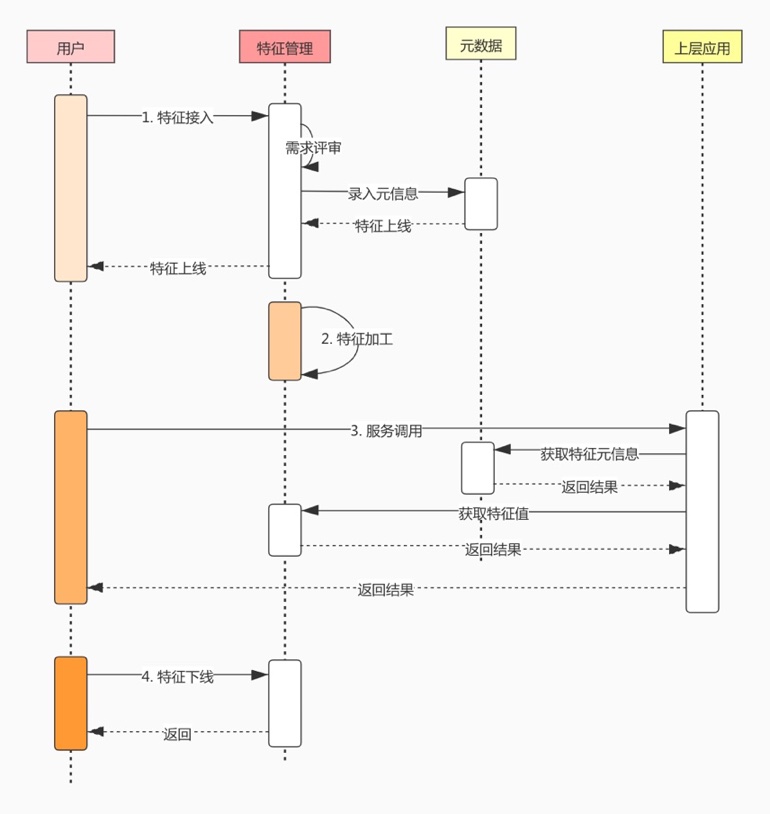
从时序图中可以看出,特征的生命周期可以拆解为四个部分:
- 接入特征
- 对特征进行加工
- 使用特征
- 特征下线
实时特征和离线特征只是处理方法上有区别,但它们生命周期是一致的,所以在时序图中没有区分。
从特征的生命周期中可以看出特征管理系统必须能够管理特征的元信息,例如特征的接入、上下线;将特征按照某种逻辑重新加工;给上层应用访问特征提供统一的接口。
特征管理系统
根据特征的生命周期可以将特征管理系统大致划分为元数据管理、特征加工、特征服务几个模块,每个模块只负责自己的逻辑即可,它们相互解耦,也利于扩展。本节主要划分每个模块的功能边界。
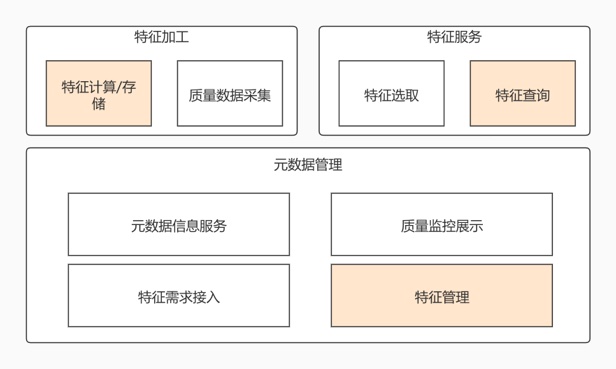
最重要的部分都用色块标示。
元数据管理
元数据管理模块是整个系统的基石,它管理着所有特征的元信息。这个模块可以划分成四个部分:
特征需求接入
负责对接用户的特征需求,录入接入特征需要的所有信息。在特征上线前的所有流程都应该在这个模块。
特征管理
负责特征的状态、权限管理。特征的上下线,隐藏均通过这个模块处理。当特征需求评审通过之后,生成对应的特征加工任务。
元数据信息服务
为外部提供特征的信息查询
质量监控
用于展示特征的质量监控信息,实时特征和离线特征会有一定差别。当数据有异常信息时,及时发出报警,通知用户或者开发处理。并且有着可视化的监控指标信息,也能给客户安心的感觉。
特征加工
特征加工应该算是整个系统的发动机,它负责将外部数据整合为特征。实时、离线特征的加工任务提供的功能是差不多一致的,都是获取一个数据源里的数据然后加工计算成需要的数据然后再存储到另外的数据源中,因此它们对外的接口基本是一致的。但是由于数据源的存储介质和时效性的区别,它们的技术架构也会有一定的不同。
特征计算/存储
特征计算其实就是端到端的过程,理解端到端对理解整个系统的设计非常重要。分为实时特征计算和离线特征计算。特征的存储介质主要有hive、codis、fusion、es,特征的用途不同,存储的介质也会不同。
质量监控数据采集
采集特征在计算过程中的监控指标,然后发送到元数据管理系统。
特征服务
提供特征服务的能力,使外部系统能接触到特征数据。
特征选取
上层应用在访问特征数据时,有可能需要事先选取下要访问的特征、访问方式,因为不同的存储介质、不同的应用,访问方式也不一样。
特征查询
使外部用户能直接查询特征,提供的服务方式可以是多样的。hive中的数据离线查询,fusion和codis通过微服务查询或者sdk方式。
实时特征加工
实时特征与离线特征的主要区别在于时效性,因此实时特征加工任务最需要考虑的特性是低延迟。Flink是一个高效的流计算平台,当前模块是基于Flink来实现的,会建立多个Flink任务来完成特征计算。Flink也是支持批处理的,后期部分离线特征任务可以考虑也使用Flink来完成。
特征计算过程
分成两个步骤:
任务管理
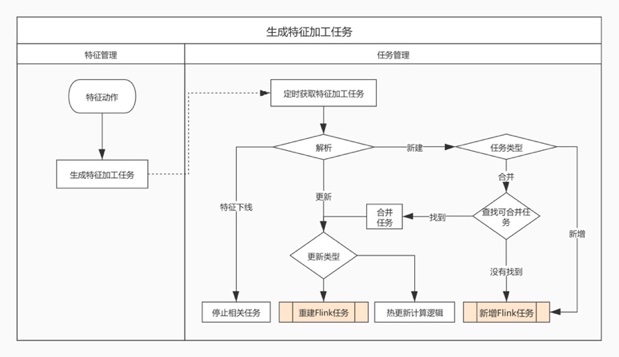
当特征新增、逻辑修改、下线时,会生成一个任务。任务管理模块会定时读取任务,来触发相应的动作。为了加工特征,可能会产生很多独立的Flink任务,任务之间相互隔离可以使任务之间不会相互影响,提高特征的稳定性。但是如果为每个特征都生成一个Flink任务,是不必要并且会浪费大量的资源,当特征的数量过多时,这种方案也是不可行的。因此需要合并部分特征任务,减少任务数量。
合并任务主要依据于几个因素:
- 用户指定多个特征共享同一个任务
- 根据特征的source、sink配置判断是否能进行合并,例如:同一个topic的产出的特征并且存储介质一样,则可合并。
- 如果source的qps较低,即使source、sink配置不一致也可合并到一个Flink job中。
在任务合并之前需要通知并让用户来确认。
执行Flink任务
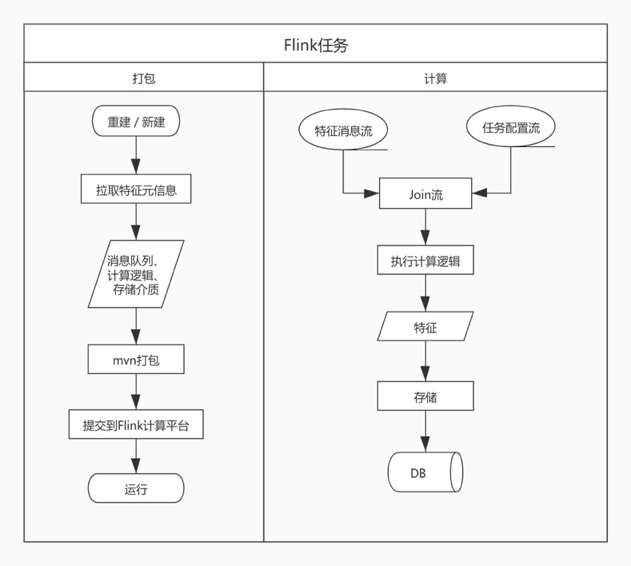
本模块可以分为打包和计算两个过程。打包是自动根据特征的元信息在服务器上生成个jar包,并提交到公司的Flink计算平台。
计算过程也较为简单,Flink任务在特征消息流之外还会额外消费任务配置流,任务配置流的主要作用是通过下发与任务相关的配置,例如:计算逻辑的修改,再通过广播的形式将配置发送到整个任务中。由于任务事件较少,不会对Flink任务的计算流程产生影响,因此所有Flink任务可共享同一个任务配置流。
如果DB能支持幂等性操作,则数据是能达到强一致性的。不过大部分DB都不支持,因此数据最终能达到什么样的一执行是和当次任务的配置(存储介质、计算逻辑)相关的。
标签系统的实时特征都是以hash的数据结构存储到redis中,操作为HINCRBY和HSET,在这个场景下可以结合Flink的checkpoint来达到数据的最终一致性。
质量数据采集
实时特征的质量数据分为两部分:Flink任务在执行过程中产生的指标,实时特征准确性校验数据。
Flink任务监控指标
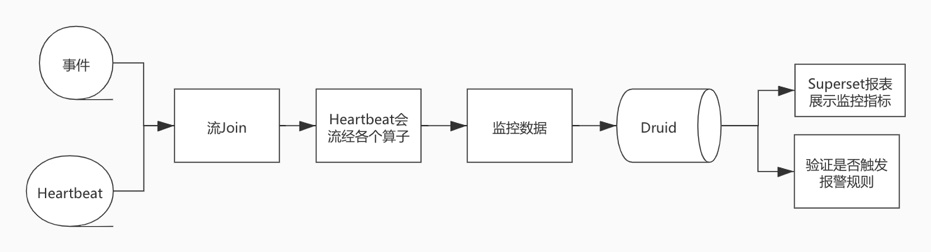
通过Heartbeat可以计算每个任务中每个节点耗费的时间,系统的可用性。参考文章。
这一块再进一步,可以让用户通过配置的方式来监控某个用户在某个时间段内的所有相信,包含对应的消息、产生的特征值,用于验证和排查问题。
准确性校验
实时特征在生产出来之后,需要进行准确性校验,可以通过与对应的离线特征进行比对来校验数据是否准确。
由于这块的成本较高,可以选择对重要些高的特征进行校验。
特征服务
这个模块主要是为了统一外界访问特征的方式,统一的访问方式也使外界可以方便的接入特征。
模型与特征管理平台之间的交互流程
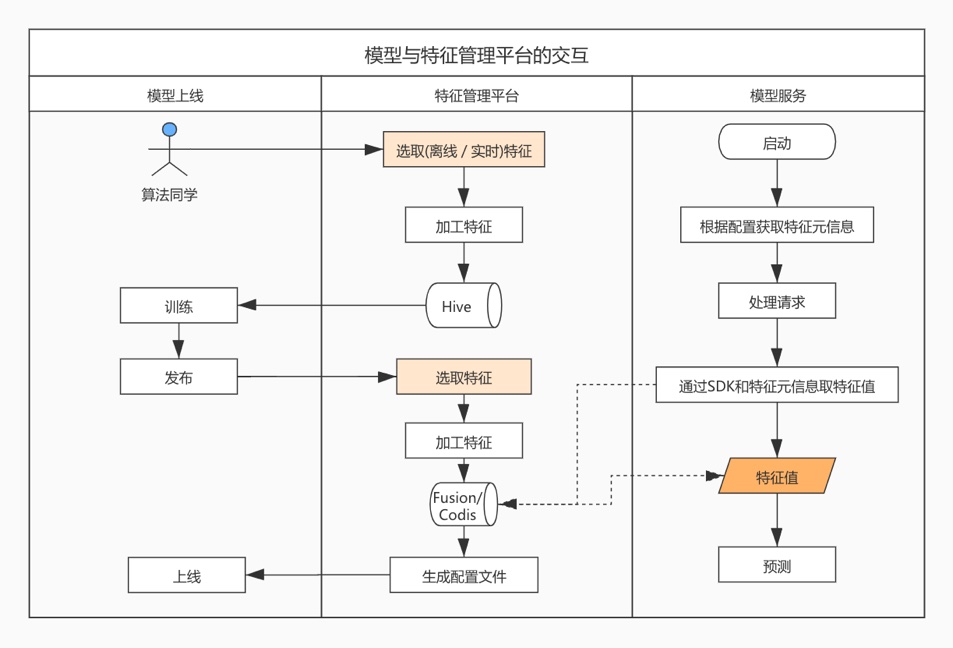
特征选取
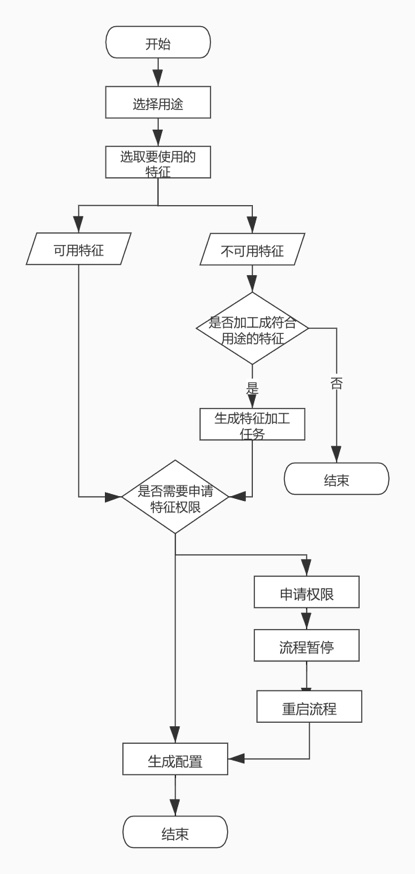
在用户能真正访问特征需要校验其是否有权限,并且特征是否能满足对应的用途,如果不满足可以提交个特征加工任务,将特征重新加工。例如模型服务在上线时需要选取相应特征,如果某个特征只存在于hive中,那就需要将这个特征录入到fusion中,这时就可以新建个离线任务来执行。
不同的用途对特征的访问方式也不一样,生成的配置也不一样。例如:模型服务用途生成的是一份特征配置;而通过api来访问特征生成的就是一份访问说明文档。
特征查询
查询方式可以有多样的,离线查询、API、SDK方式。
以模型服务举例,模型服务一次访问的特征过多,为了优化性能,需要通过提供的SDK和建议的方式来查询特征。其中模型服务在启动时,即可以通过访问特征管理系统来更新配置信息,也可以通过生成的配置来获取特征元信息。SDK的使用方式可以参考下醉酒模型的流程。