服务超时问题
背景
上游一个服务在调用我们服务的时候突然出现了大量的超时。首先怀疑的是docker机器又挂掉了,然后看了下服务的调用量监控,如下图。

从图中可以看出服务是在某个时间点突然没有任何流量(或者是服务本身问题导致不能上报监控指标)了。
服务之间是通过thrift进行通信的,thrift server的工作模式为TThreadedSelectorServer。
问题排查
首先是登录到服务器上验证docker是否正常或者服务是否存活。随机找了几台服务节点,发现docker和服务进程都存活着,说明可能是服务本身出问题了。
使用
tail -f error.log查看服务的错误日志,观察到一直在出现大量的异常。1
2
3java.util.NoSuchElementException: Timeout waiting for idle object
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:448)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:362)而且这个异常的出现时间点和监控出现异常的时间点相吻合。这会导致响应客户端请求的时间增长,导致客户端请求超时从而关闭连接。
通过
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'查看对应端口的网络连接情况,单台服务器上有八万多个close_wait连接。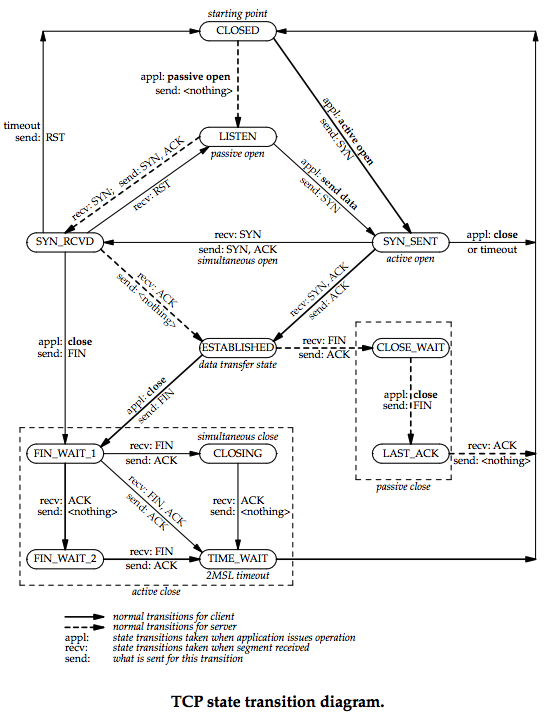
查看tcp状态转换图可知客户端一直大量的新建连接和关闭连接,并且服务端没来得及处理关闭连接事件(调用close()方法)导致服务端出现了大量的close_wait。
大量close_wait造成的影响
由于close_wait是系统层面的问题,比问题1容易定位些,所以先分析下问题2。
8万多的close_wait连接说明服务进程中至少同时接收了8万个客户端的连接,其能造成的影响大致有以下几点:
- 连接不停的创建和关闭,会增大请求访问耗时,消耗服务器的CPU资源。
- 一个tcp连接是会同时占用堆内和堆外内存的,过多的tcp连接肯能会导致OOM,服务器内存不够用的情况,在极端情况下还可能把服务给压垮。tcp连接占用堆外内存情况可参考文章
- 线上服务能在同一时刻接受的最佳tcp连接个数上限时根据服务处理tcp连接的线程模型和IO模型共同决定的,由于服务使用的是nio来处理网络连接,处理接收连接和关闭连接事件是在单独的线程池,与处理业务逻辑的请求是隔离的,所以这个问题的只是影响了网络连接这块的,当前的这个服务来说不算特别大。
连接池问题
java.util.NoSuchElementException: Timeout waiting for idle object 是因为在从连接池里取新redis连接超时导致的。导致这个问题可能会有以下原因:
- 连接在用完之后没有及时释放,一直没有可用连接
- 网络抖动导致请求耗时增大、请求总耗时增加,从而引发超时,使连接池中的连接一直处于建立连接、关闭连接的状态
- 并发过大导致排队时间过长
当前的服务运行已经超过一个月,这次是突然几十台节点同时出现问题,并且流量没有变化。因此基本上可以排除1、3,最可能的是使用的redis集群出现了问题。而在redis集群出现问题又会不会导致问题1、3发生,由于没有足够信息,现在很难下结论。
验证
由于当时的现场信息保留不完整,现在推测一下问题产生的原因。从前面的问题推导过程中得出网络抖动是最可能导致这次问题发生的根本原因,所以我们先模拟一下网络抖动。
复现过程并不复杂,主要分为两步:
网络抖动,在mac上模拟网络抖动的方法。
在服务稳定运行一段时间之后,模拟网络延迟、丢包的情况,最大程度的去还原问题现场。1
2
3
4
5
6
7
8
9
10
11
12# 打开防火墙
sudo pfctl -e
# 设置网络环境
sudo dnctl pipe 1 config bw 10Kbit/s delay 300 plr 0.09
# 限制端口
echo "dummynet in quick proto tcp from any to any port 6379 pipe 1" | sudo pfctl -f -
# 清除设置
sudo pfctl -f /etc/pf.conf
sudo dnctl -q flush
sudo pfctl -d压测,压测过程就不描述了,根据服务类型、运行环境的不同,压测的过程、参数也可能不一致。
压测的目的主要是在于看看在高负载的情况下,服务是否会出现同样的问题。
结论
看下当前服务的执行逻辑,来分析下连接池问题如何导致整个服务处于不可用的状态。
建立连接过程
处理请求流程图
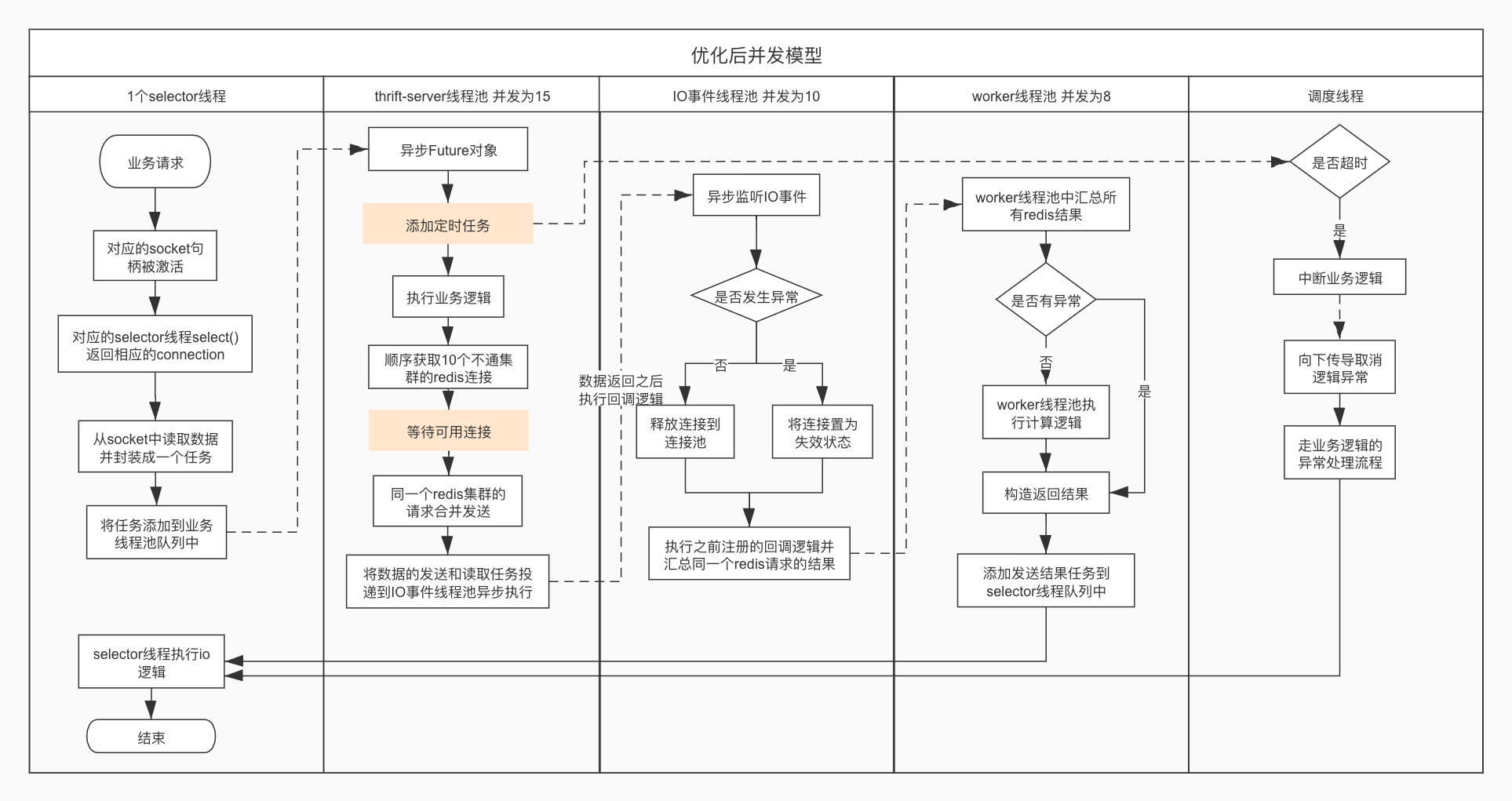
上面这个流程图省略了业务处理逻辑,只展示了各个线程之间的交互关系。从流程图中很容易的可以看出在redis集群出问题时,服务中有两个逻辑漏洞:
- 当
等待可用连接步骤出现了问题时,会导致thrift-server线程池中积累大量任务,没有机制能终止这些任务的等待 添加定时任务的流程过于靠后,导致它只能终止已经响应过的请求,不能终止未被响应的请求。
这就会导致了上游调用超时,并且后续的请求基本都会超时,这也就能解释为什么一个短暂的网络抖动导致上游持续超时。
解决方案
有了结论,找到解决方案就非常容易了。
快速解决方案
当前问题快速的解决方案是服务进行重启,但治标不治本。
优化程序
不管是作为客户端还是服务端都需要设置一个服务熔断策略,设置请求的超时任务在流程中应该在执行业务逻辑之前。服务在不可用的情况下,继续请求只会加大服务的负载,更难恢复,原因如下:
- 客户端在访问某个服务时出现了大量的超时情况时下,再持续的创建新连接发送新请求,也会严重的拖累自身。
- 服务端在发现服务基本不可用时,再继续接收新的业务逻辑请求时,会让本就超负荷运转的服务更难恢复过来。
优化后的并发模型为: