在线服务性能优化
背景
组内有好几个线上服务,除了业务逻辑不一样,请求处理过程基本上都是一致的。这些服务的执行逻辑都非常简单,但是有几个问题:
- 单机QPS很低,需要很多台机器
- 99分位耗时比理论上的长很多
- 在单机qps达到上限时,服务器的负载却非常低
上面的这些问题在财大气粗的公司面前都不是问题啊,性能不够加机器!性能不够加机器! 上游再一次过来反映超时问题时,为了壮年程序员的尊严,这次刚好有时间决定不再单纯的加机器,要把这个程序优化一下,用一次屠龙技。
技术栈:
语言:java
通信方式:thrift,server模式为THsHaServer
redis客户端:jedis
模型:xgboost
执行环境:docker,8核 8G
缓存集群:通信协议为redis,但实现方式和redis不一样优化过程
想要提升程序的性能,首先需要找到程序的瓶颈所在,然后有针对的去进行优化。
流程分析
优化前流程图
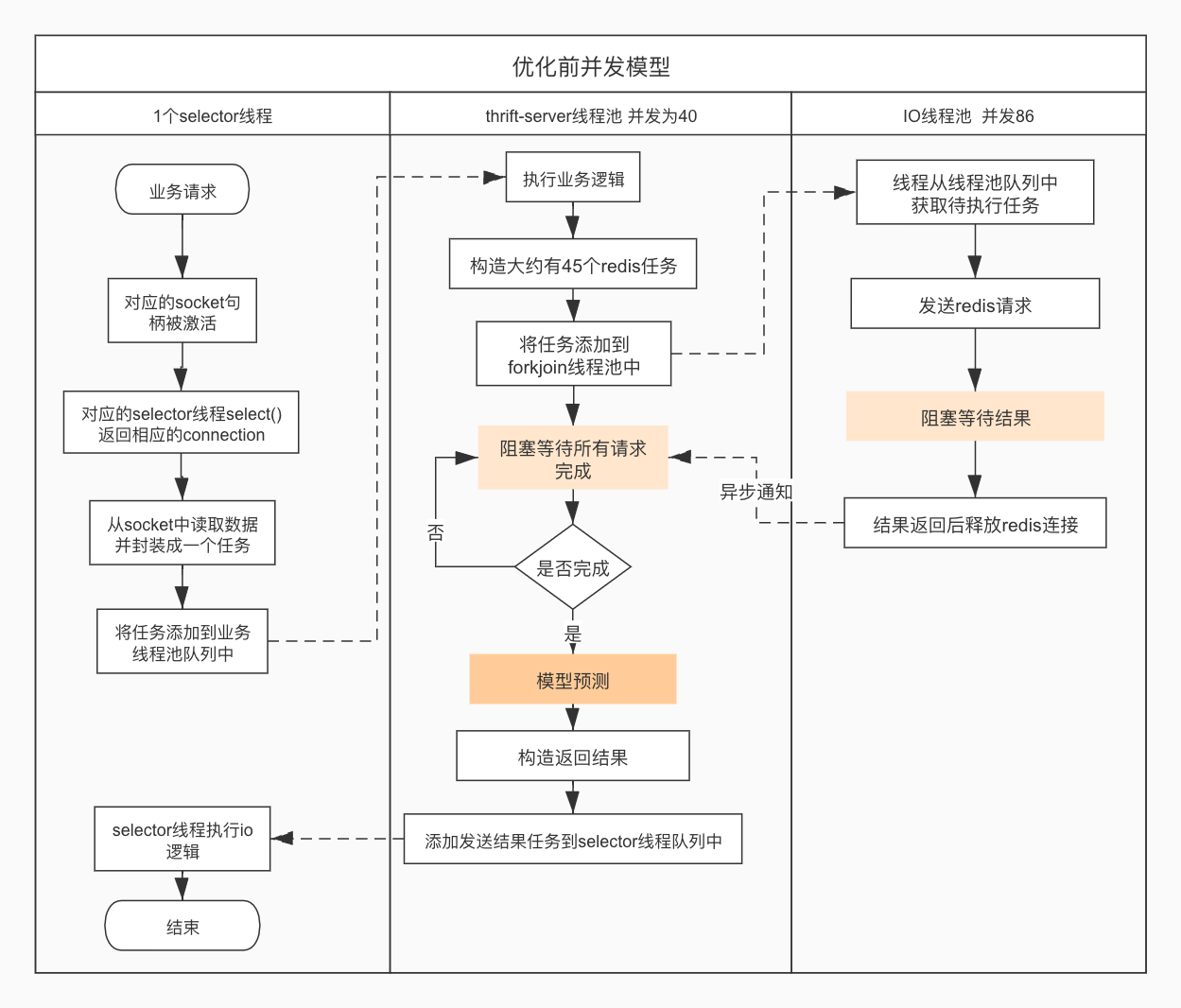
这个流程图省略了业务处理逻辑,只展示了各个线程之间的交互关系。构造redis请求的那部分逻辑,其实使用了两个forkjoin线程池,但它们两个的逻辑非常类似,为了简化把它们合并到一个流程中了。流程图中有两个深红色的步骤,很明显的看出两个明显能影响性能的地方。
结合服务的执行环境,可以总结出以下问题:
线程数过多
由于操作系统对线程的抢占式调度,线程频繁的上下文切换会带来几个问题:
- 系统指令执行时间增长,对应的指标值为
cpu.sys,造成cpu执行时间的浪费 - 单位时间内分配给执行用户态指令的时间减少,对应的指标为
cpu.user - 综上可看出,其不仅使机器负载升高,也会使执行单次任务耗时增长
两个阻塞
流程图中标红的两个步骤在执行时都会阻塞线程。其中thrift-server是在阻塞等待所有的redis结果,forkjoin中是在阻塞等待redis返回结果,网络通信使用的是同步io模式。
线程从运行状态切换为阻塞状态时,会发生一次线程上下文切换并且线程需要等待被重新调度。这是在操作系统层面的影响。
假设服务同时接收到40个请求,从流程图中可以看出,此时服务最多同时能发送86个redis请求,而要想让服务能通时执行40个任务,则必须要同时发送2000 = 40 * 20个redis请求。如果将forkjoin的最大线程数调整到2000明显是不可以的,实际在这个服务最初的版本中是没有限制forkjoin的最大线程数的,所以在服务负载升高时,服务器开启的总线程数也一直在飙升,此时就会收到疯狂的服务器负载报警,且请求调用耗时也非常高。
- 由于阻塞线程的操作,要想增大程序的并发就只能多开启线程,而线程数量多了就会影响程序的性能
- 使用同步io方式来发送redis请求,同时发送的redis请求数量非常有限。这不仅严重拉低了qps,而且也使99分位耗时增长。
任务无限期等待
从上面也可以看出任务没有超时的限制,可以无限期的等待下去。这会造成以下影响:
- 如果客户端没有设置超时时间,可能会无限期等待下去,可能会拖垮客户端。
- 如果客户端因为超时而取消了这次任务,那么这个任务再被执行是没任何意义的,而且还会挤占其它任务的执行时间,甚至造成程序的雪崩。
总结:
从前面的分析可以看出,现在程序的瓶颈主要是查询redis过程,其次是thrift-server中线程的阻塞逻辑。
流程优化
由于程序的JVM GC监控指标在正常范围内,并且改动架构还需要重新观测GC情况,所以先做程序架构上的改造。
查询缓存过程
这主要是一个网络优化的过程,业务层通常是从以下几点入手:
- 减少通信次数,即合并多个请求成一个网络请求。因为我们公司的缓存集群实现方式和redis不一样,使用pipeline、mget对性能提升有限,甚至降低。
- 使用异步IO,不仅能减少使用的线程数,而且能增大同时发送的redis请求数量。
当前使用的redis client是jedis,用一个开源的异步redis client lettuce代替,它的底层使用的neety。
thrift-server
使用AsyncProcessor来将其改造成异步。
任务增加超时限制
给最上层的CompletableFuture设置一个超时逻辑,当任务执行时间超时就取消CompletableFuture的执行,并将这个取消通知逐层传递下去。
流程优化后的流程图:
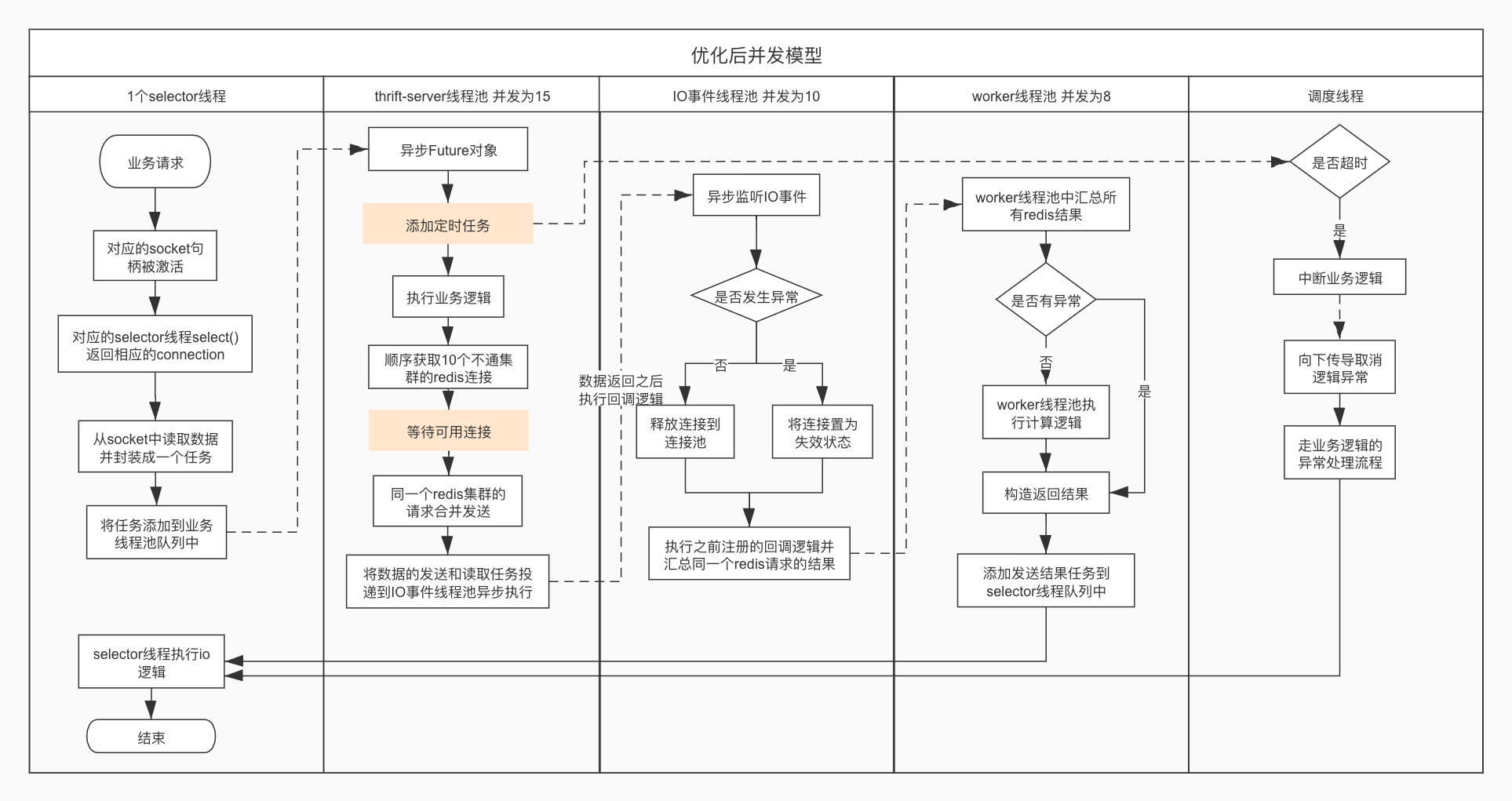
上面这个流程还是有几个薄弱环节,在一次偶发事件上,出了一次问题,相应文章。
有了新的流程图,代码改造就纯粹是一个按图实现。为了减少改造过程中引入新的bug,要秉持一个原则:尽量复用之前的代码。
压测
压测工具使用的QA组提供的工具goperf2,使用jprofiler监测jvm进程执行情况。jprofiler这个工具非常重要,通过它的可视化界面可到jvm进程中所有线程的执行状态,例如:锁导致的阻塞、线程的从繁忙与空闲的切换状态,然后根据这个状态再去调优一些参数。
初步的压测结果证明了前面的优化思路是正确的,还需要再填一些小坑道路才能平坦。压测过程中发现的问题:
- 当在压测时,服务给出空响应耗时特别长。空响应是不做任何业务逻辑,收到请求就直接返回。
原因:selector线程处理不过来了。 - 压测程序跑了一会之后,服务器上出现大量time_wait,就提示不能在分配连接句柄了。典型的tcp面试题,是因为端口不够分配或者进程的句柄数达到最大。
- 服务器上也出现了大量的time_wait。lettuce连接池参数问题,使连接不停的关闭。
- 单次访问耗时不稳定。jvm类加载过程、连接池初始化、线程池初始化的问题。
- 连接池borrowObject耗时很长,参数优化。
- 正则表达式性能问题,重新为相应的字符串操作。
- java stream耗时。
- hashmap不停的新建。
类型 | qps | 平均响应时间 | 90分位 | 95分位 | 99分位 | 99.9分位 |
|---|---|---|---|---|---|---|
| 优化前只取45个实时特征 | 2951 | 6.761 | 7 | 10 | 50 | 55 |
| 优化后只取45个实时特征 | 11781 | 2.1 | 3 | 3 | 4 | 9 |
| 优化后只取45个实时特征,三个进程 | 17218 | 2.25 | 3 | 3 | 7 | 11 |
| 优化前预测 | 1774 | 14 | 19 | 35 | 61 | 68 |
| 优化后预测 | 2702 | 9.2 | 11 | 12 | 14 | 17 |
| 优化后预测 三进程 | 4705 | 8.5 | 13 | 14 | 17 | 24 |
压测中用到的命令
查看tcp 半连接和全连接队列情况 netstat -s | egrep "listen|LISTEN" ;ss -lnt
统计tcp连接各个状态数量 netstat -n | grep <port> | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
xgboost sdk性能问题
经过对程序架构、代码实现的优化,新版的程序终于上线了。上游也不再反馈超时了,机器负载也不高了,饭量也大了。
但是某天再看监控的时候,发现JVM进程竟然开启了800多个线程,远远超出理论上50个以内的线程数量。
就简单的说下分析过程和原因吧。
定位过程
验证监控是否出错
通过这几个命令来查看进程的线程状态和数量, 发现和监控一致,证明监控没有问题。
1 | ps -eo nlwp,pid,args --sort nlwp |
验证jstack问题
通过查阅jstack文档发现,使用jstack <pid>只会输出受jvm进程管理的线程,只有jstack -m <pid>才能输出.so库开启的线程,但是jstack -m打印的堆栈信息不全。
定位开启非jvm线程的代码
打印进程堆栈,gstack <pid>,发现除了jvm线程之外,大多线程的堆栈信息都是一样的且都包含了libomp.so。这个库是用于c/c++中的多线程库,相关资料openmp。也就说程序中有代码调用libomp.so开启了大量的额外线程。
而开启线程肯定是要经过系统调用的,通过strace命令可以跟踪到是哪个线程开启的libomp线程。在这个过程中,需要jstack打印出jvm线程堆栈,通过比较线程id可以准确定位具体的jvm线程。
最后定位到是算法组同学给出的模型jar包调用的。
xgboost
定位到算法组给出的模型jar包的问题之后,开始浏览他们的代码,最后发现根源问题在与xgboost。相关代码如下图。
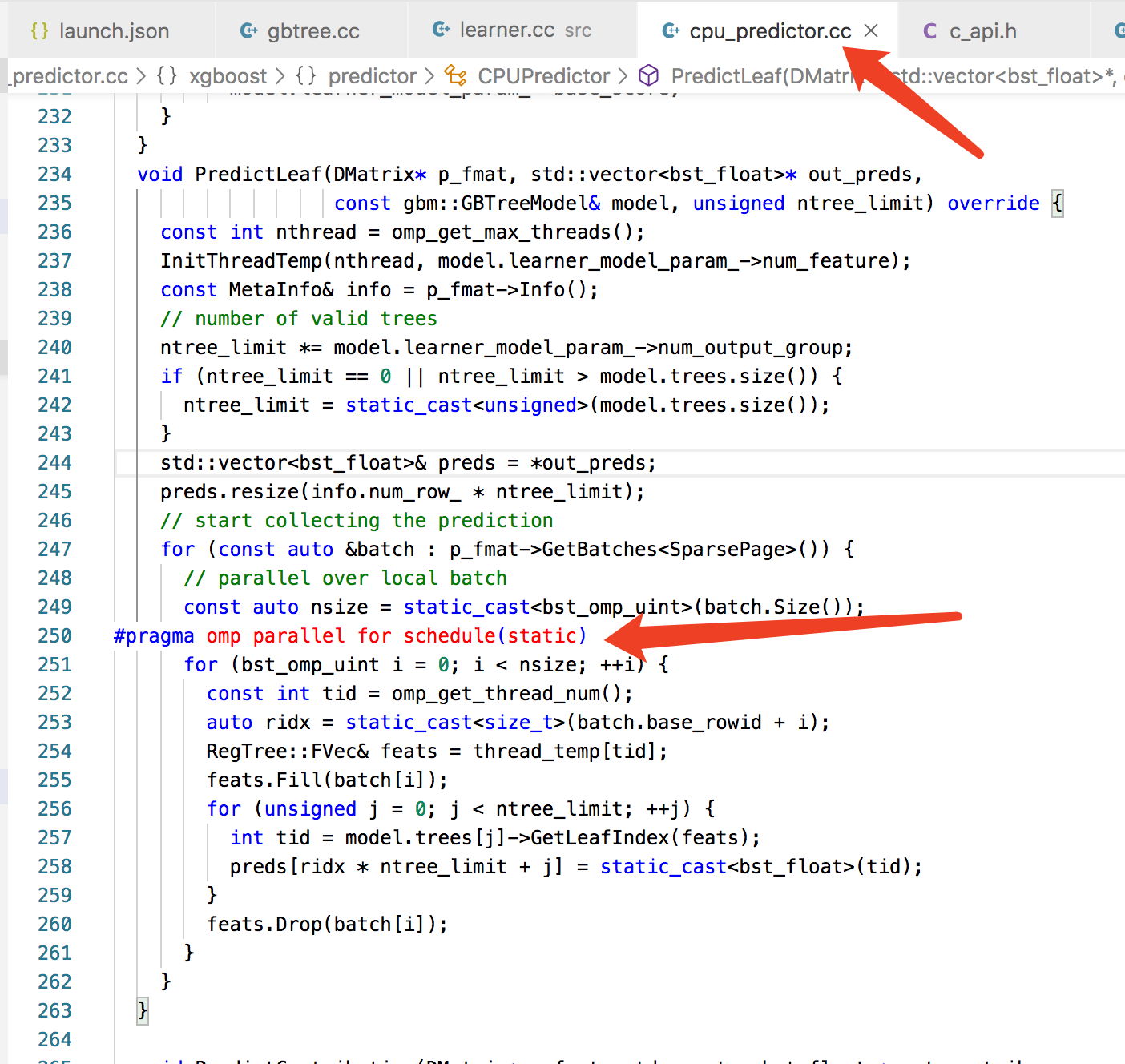
jvm线程再调用Predict方法时都会开启omp_get_thread_num个线程,但是一个jvm线程只会开启omp_get_thread_num个线程,最终的总的xgboost线程数量刚好与count(jvm thread) * omp_get_thread_num吻合。
除了xgboost c库的问题之外,官方的java库也存在一个问题。在使用xgboost的时候,一般只会创建一个Booster对象,然后多线程调用booster.predict()方法,最终都会调用一个同步方法。
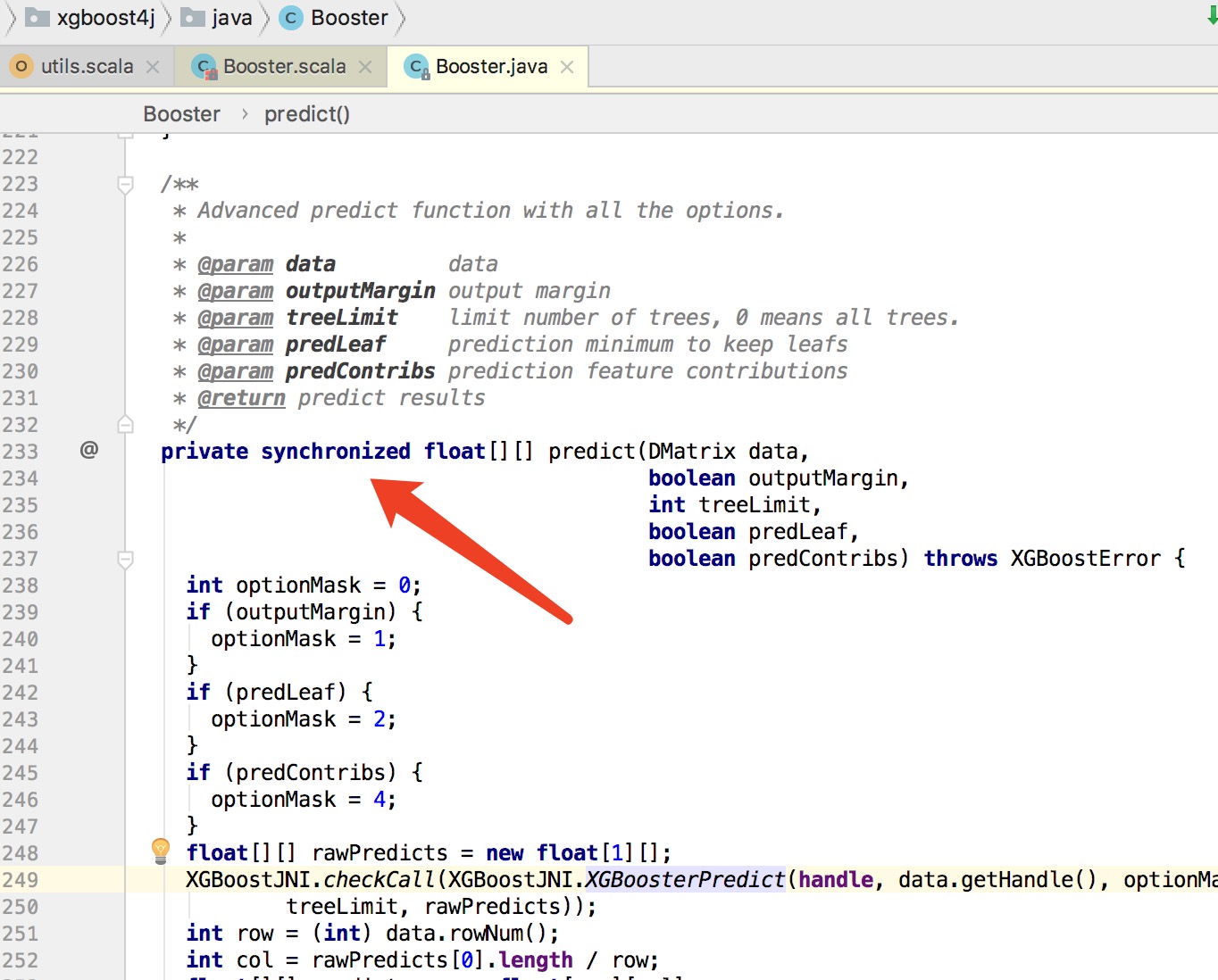
这个方法是个同步的,在多线程调用的时候,同时只有一个线程能执行预测方法,其它线程进入到阻塞状态。在没有竞争的情况下,predict()方法的耗时在1ms左右,当竞争激励时,方法耗时甚至能增加到20ms,且没有上限。这在对请求耗时敏感的业务场景下,是一个不可接受的问题。
解决方案
解决方案有两种:
程序在启动前添加环境变量,例如
OMP_THREAD_LIMIT=1 control.sh start。用来限制omp开启的线程数量。使用纯java实现的xgboost库来替换xgoobst的官方库,
这个服务还遇到过一个堆外内存问题,不过定位过程足够再写一篇文章了。
进一步的优化
至此,对服务的优化效果已经达到预期。但其实还可以做出进一步的优化,但耗费的精力就非常大了。
对程序优化的本质是考察程序员对操作系统相关知识点的理解程度:
- 进程/线程原理,线程是操作系统执行的最小单位,如果真正的理解这句话,那么再做任何架构方面的优化就非常容易了
- IO原理,相关知识点:存储、总线、DMA
- 线程之间的同步最终也会反映到线程的执行
更近一步的优化思路,由于多线程之间势必会涉及到资源的竞争,这一般是通过锁来进行同步。那么找到对程序中的同步点并且尽量消除这些同步点对程序的性能会有非常大的提升。优化同步点是一个非常关键但也非常耗费精力的事情。
程序运行起来,那么肯定就是要接受输入并且处理再输出结果,那么追踪一条请求的数据走向,那么就能找到在完成一次请求的过程中,都有哪些同步条件发生了。而一个多线程程序是以线程池单位来完成整个程序的执行逻辑,线程池内的线程一般执行的是同样的逻辑。先粗粒度的来分析数据的同步关系,再分析一个线程池内线程之间的同步关系。
单个进程不能避免锁竞争,可以通过开启多个进程来完成减少锁的影响。在这次的压测过程中,也测试了多进程网络服务的性能。多进程网络服务,可参考这篇文章。
参考
- 性能优化模式
- 【书籍】现代操作系统
- jstack的工作原理
- openmp
- Guide into OpenMP