ZooKeeper介绍
大部分高可用的场景中都会使用到ZooKeeper,例如:Hdfs,Hbase,Flink。
概要
应用场景
ZooKeeper应用场景非常广泛
分布式锁
高可用
Hbase的Master选举,Flink的JobMaster选举。。发布/订阅
微服务注册中心
分布式队列
重要概念
ZooKeeper对应用层来说,核心的就两点Znode和Watcher
Znode
zk是将所有的数据组织成一颗树,类似于文件的组织形式。例如:/flink/cluster, /flink 和 /flink/cluster都是Znode,其中后者是前者的子节点。
节点类型
节点类型可以分为两个维度:
| 持久性 | 有序性 |
|---|---|
| 持久节点 | 有序节点 |
| 临时节点 | 普通 |
这两个维度一共可以组合出四种类型的节点。
永久节点 当节点被创建时,除非显示调用delete命令删除,否则节点会一直存在。
临时节点 客户端连接与zk服务端连接断开时,这个节点就会被删除。
有序节点 可以在一个节点下创建有序的子节点,每次创建都会生成一个带有序号的子节点。例如:create -s /lock_test/lock 1这个命令执行两次,会生成两个节点 /lock_test/lock0000000000 /lock_test/lock0000000001
节点包含很多属性,通过get命令可以看到Znode包含的属性。
1 | [zkshell: 12] get /zk_test |
节点分为临时节点和持久节点,临时节点在session失效时就会被删除,持久节点会一直保存。
Watcher
当Znode有变动时,会通知给监听者。Master选举的过程就是master节点会在zk中创建一个znode,拿到这个master节点权限的节点就会做为主master节点,当主master节点异常挂掉时,备用节点会收到通知,然后拿到znode权限的节点就会升级为主master了。
集群架构
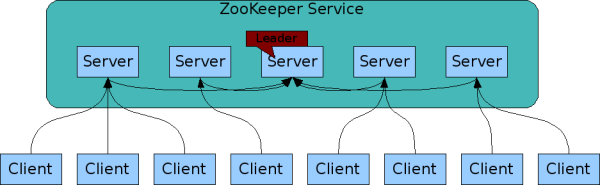
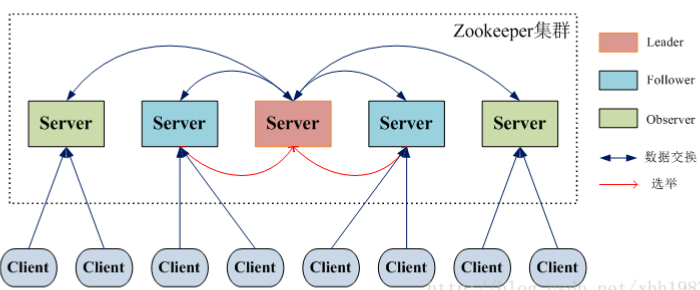
集群中会有多个节点,一个Leader节点
选举过程
zab协议
群首执行Client提交的请求,并形成状态的更新,就称之为事务。事务是原子性执行的,Znode数据和版本变更是原子的。事务还具有幂等性。
保障:
- 保证同一时刻只有一个leader
- 事务严格按照顺序来执行
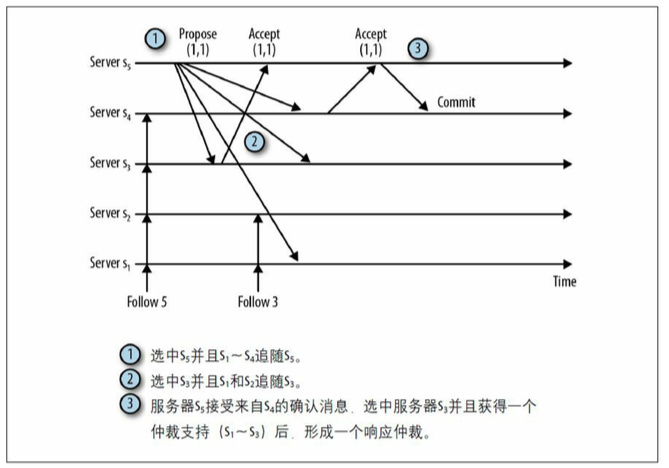
服务器中还是可能存在两个leader的,但是由于一个提案需要半数机器同意才可以,而一个新的leader产生也需要半数以上节点同意才可以,这样就会保证支持新群首的仲裁机器与确认事务T的仲裁机器至少有一台是重合的,这就能保证了系统的正确性,事务不会丢失而且系统状态也不会被破坏。
存储
zk中的数据都是存储在内存中。
持久化
快照
事务日志
故障处理
考虑以下的情况:
- 客户端提交事务到zk,zk在事务成功提交之后,client收到相应之前,网络断掉
- 客户端在发送请求之后,zk leader 宕机
- zk 在响应一个事务的过程中,leader宕机
- 多集群中的一个节点与zk建立连接后,身份变更开始更新自己系统的数据。因为系统因为负载过高与zk断开连接,但是其已经将更新操作放入执行队列中,等待cpu时钟周期。
- 一个分布式系统使用zk来选举master节点,当一个节点与zk断开连接时,其它节点接管master,这个时候会出现双master情况吗?