Flink源码分析-数据流转
将一条消息从被Flink job消费到最后被sink下来的整个过程划分成两部分,算子的逻辑处理、task之间的消息传递。其中算子的逻辑处理需要用户参与,task之间的消息传递一般是不需要用户参与的,但是了解其实现过程,对理解Flink的原理是非常有帮助的。
概念
在Flink job被执行前,会生成StreamGraph、JobGraph、ExecutionGraph。
StreamPartitioner 流分区器
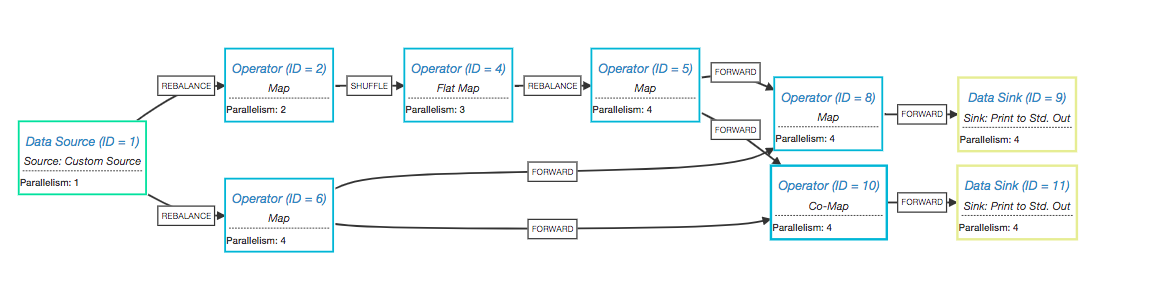
分区器决定上游算子的子任务以何种方式将消息发送给下游算子的子任务,也就是如何对数据流进行物理分区。流分区器的类型有:
- BROADCAST 上游的消息以广播的形式发送给所有的下游
- REBALANCE 负载均衡的方式发送
- SHUFFLE 随机选择下游
- CUSTOM 用户自定义分区方式
- HASH 用户自定义分区方式,与CUSTOM区别是专用于
KeydStream - FORWARD 点到点进行发送,这种分区方式下消息只是在进程内传递。
中间数据集

![]()
数据从开始到结束大概会经过以下过程:
- SourceFunction 产出 Record
- 通过Partitioner 为此record选择要发送到哪个channel
- 发送到ResultPartition
- 选择ResultSubpartition
- 通知JobManager
- JM部署下游
- 下游Inputchannel 请求 ResultSubpartition
参考: